set 은 <set>이라는 헤더 파일을 가진다.

std::set유형의 고유한 개체의 정렬된 집합을 포함하는 연관 컨테이너입니다 Key. 정렬은 키 비교 기능 Compare 를 사용하여 수행됩니다 . 검색, 제거 및 삽입 작업에는 로그 복잡성이 있습니다. 세트는 일반적으로 레드-블랙 트리 로 구현됩니다.
Red-Black-Tree 란
binary-search-tree의 한 종류이다.
스스로 균형을 잡는 blanced tree이고
binary serch tree의 worst case의 단점을 개선시킨 트리이다.
모든노드는 black 아니면 red이다.
nil노드는black이다.
red노드는 연속하지 않는다.
임의의 노드에서 자손 nil노드까지 가는 경로의 black의 수는 같다 (자기자신은 카운트 제외)
위 같은 특성을 가지는 tree이다.
binary-search-tree는 sorting되다 보면 한쪽으로만 정렬되는 최악의 경우가 있다
그런 경우에 o(n)의 TimeComplexity를 가지게 되기 때문에 이를 blance를 맞추어 이러한 경우 없이
항상 o(log n)의 TimeComplexity 가지도록 하는 역할을 하는게Red-Black-Tree 이다.

이렇게 1,2,3,4,5를
Red-Black-Tree 로 어떻게 나타내는지 확인해보자

3 을 기준으로
작은 수는 왼쪽으로
큰수는 오른쪽으로
정렬된다.
TimeComplexity
find() - O(log n)
insertion() - O(log n)
deletion() - O(log n)
insertion과 deletion은 원소 추가 삭제시 tree rebulid가 필요하기때문에 O(log n)의 timecomplexity를 가지고
find() 는 위의 원소부터 하나씩 들여다보아야 하기에 find() - O(log n) 의 timecomplexity 를 가진다.
set은 중복을 허용하지 않는다.

그냥 말 그대로 중복을 허용하지 않는다.
set은 순차적으로 정렬된다.
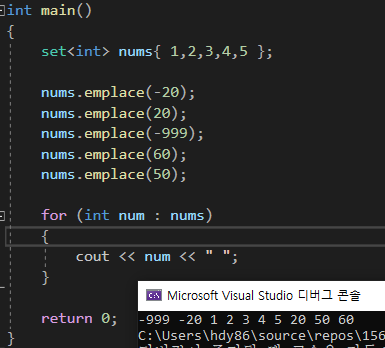
어떠한 수를 넣어도 위에서 본 tree처럼 정렬이 된다.
multiset
multiset은 중복을 허용하는 set이다.
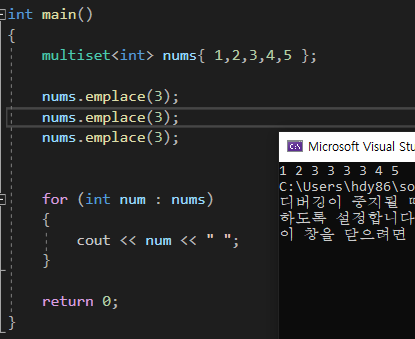
TimeComplexity는 set과 같다
find() - O(log n)
insertion() - O(log n)
deletion() - O(log n)
unordered_set
정렬되지 않은 set이다.

unodered_set은 <unodered set>이라는 헤더 파일을 가지고
find() - O(1)
insertion() - O(1)
deletion() - O(1)
위와 같은TimeComplexity 가진다.
위같은 TimeComplexity 가질수 있는 건 hash 덕분이다

내부적으로 요소는 특정 순서로 정렬되지 않고 버킷으로 구성됩니다. 요소가 배치되는 버킷은 전적으로 해당 값의 해시에 따라 다릅니다. 해시가 계산되면 요소가 배치된 정확한 버킷을 참조하므로 개별 요소에 빠르게 액세스할 수 있습니다.
이것이 무슨 말인지 확인 하여 보자.
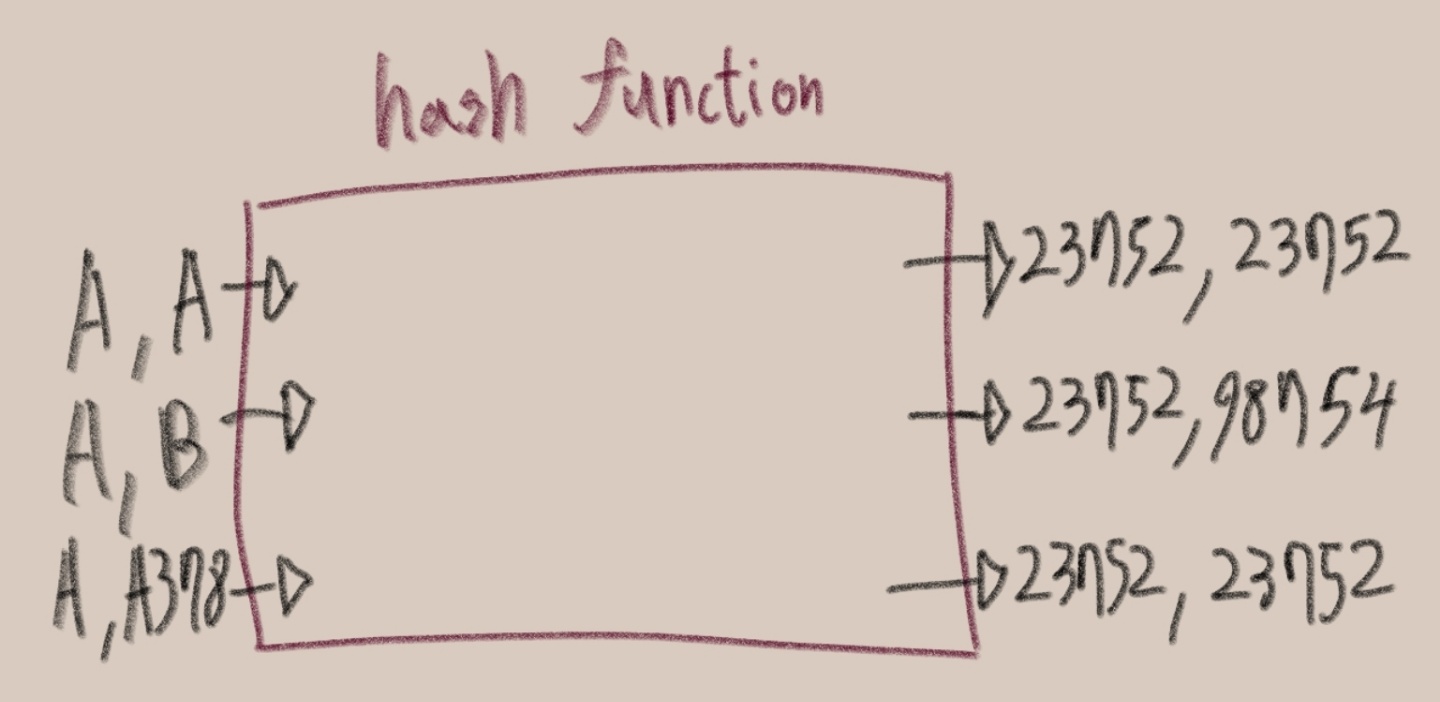
unodered_set은 이러한
hash function을 지닌다.
어떠한 인풋값이 들어갔다면
hash funciton의 출력값은
인풋과 매우다르다.
같은인풋은 값은 출력값을 같는다.
가끔 다른 인풋값이 서로 hash 값이 같을 때가 있는데 이러한 경우는 매우 낮다.
64비트 길이의 해쉬에서는 192만 개의 데이터를 다루게 되면 천만번에 한번 꼴로 충돌이 일어 납니다.
(실생활에서 비슷한 경우가 로또 1등 확률 정도이다. 0.0000122773804%)
32비트 길이의 해쉬값을 사용하는 경우 9292개의 데이터 요소를 다루게 되면 100번에 한번 꼴로 충돌이 일어 납니다.
포커에서 풀 하우스가 나올 확률인 0.1441%보다 6배나 높습니다. 0.8646%이다.
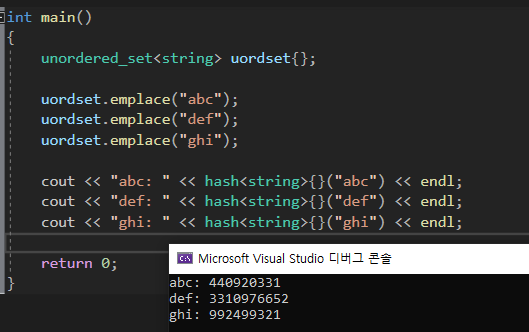
key값인 "abc" "def" "ghi" 의 해쉬값을 확인 해보면 값이 굉장히 큰것을 볼 수 있다 이러한 큰 값은 인덱스로 사용하기에는
값이 너무 크다는 단점이 있다 이러한 단점을 해결하기 위해 bucket을 만들어 bucket에 나누어 저장한다 bucket은

그러나 이 또한 vector의 capacity 처럼
다차버리면 bucket을 늘리는 과정이 추가되며 rehashing이 이러난다.
rehashing은 o(n)의 timecomplexity를 가진다. 그래서 이또한 vector처럼
reserve를 사용하여 미리 bucket을 확보해야 한다.
ex) uordset.reserve(100);
max_load_factor

최대 부하율(버킷당 요소 수)을 관리합니다. 로드 팩터가 이 임계값을 초과하면 컨테이너가 자동으로 버킷 수를 늘립니다.
1) 현재 최대 부하율을 반환합니다.
2) 최대 부하율을 로 설정합니다 ml.
max_load_factor로 언제 버킷 수를 늘릴지 지정할 수 있기도 하다.
Map
map은 쉽게 말해 set에 ket+value컨셉이 추가된거라고 보면 이해를 빠르게 할 수 있다.
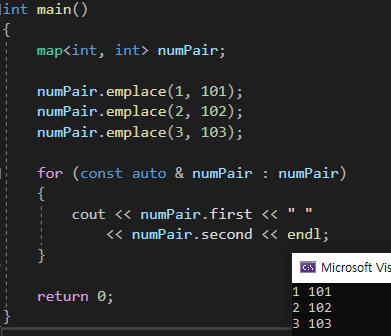
map<key, value> 이다
출력값을 보면 1에 101의 값을 2에 102의 값을 넣은 것을 확인 할 수 있다.
그리고 map또한 set과 같이 중복되는 값을 막아준다.

multimap또한 같은 원리로 작동한다
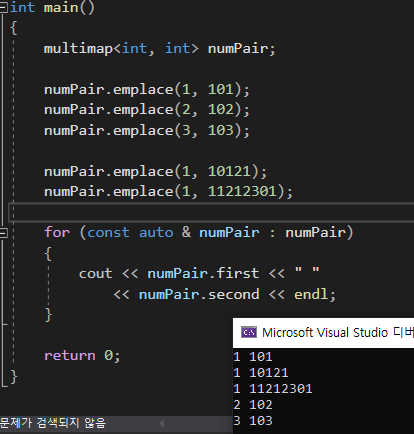
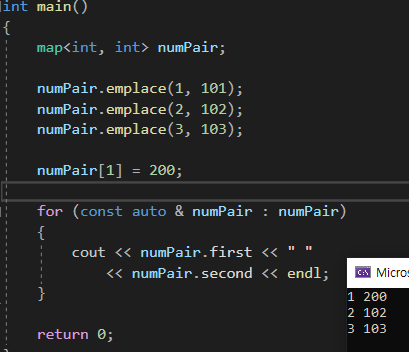
[ ] 스퀘이어 브라켓을 사용하여
오버라이드 할 수 도 있다.

이렇게 key값도 없고 value값도 없는 곳에
오버라이드를 하면 default값인 0이 들어간다.
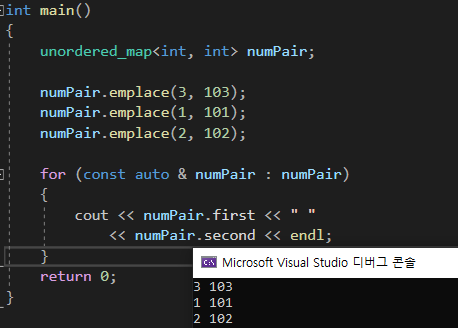
unodered_map또한 사용할 수 있다.
운영중인 카톡방입니다.
https://open.kakao.com/o/gsMhUFie
C/C++/C# 언리얼/유니티 /질문
#C++#C#언리얼#게임개발#질문#개발#자료구조#백준#프로그래머스#c#유니티#unity#enreal
open.kakao.com
'c++' 카테고리의 다른 글
| Bubble Sort 작동방식 (간단) (0) | 2022.07.13 |
|---|---|
| stack queue 스택 큐 (0) | 2022.06.09 |
| list vs vector (0) | 2022.06.06 |
| list, forward_list (0) | 2022.06.03 |
| vector 와 array c++ (0) | 2022.06.02 |




댓글